The platform team have been working hard, releasing new APIs and fixes, quite steadily over the last few months and this will continue throughout this year and beyond. If you are on our mailing list then you may already be aware of the work that has been going on and that we recently announced the release of our new Document API for general availability. We are excited about this new Document API because we believe we have provided a simpler and more efficient way for customers to upload and download documents and have aligned these APIs with our flexible object storage architecture. Read on to find out more about the design and architecture or if you just want to know how to use them skip to How to use the APIs.
Design Overview
Our document management system has an architecture that consists of a single metadata service and multiple object storage services. We provide both our own internal on-premise object storage solution as well as an option to use Amazon S3 for object storage (but can extend to others if there is future demand). The metadata service is responsible for the data that contextualizes the document, categorizing it and linking it to other entities in our systems and the object storage services are responsible for storing and retrieving the actual physical document objects. This architecture has been in place for over 5 years.
We have built a few document APIs in the past, which we use internally, and have learnt a lot from this experience in terms of what works but more importantly what does not work. From this experience we set out 3 key design goals for the new build.
- Allow for multiple object storage back-ends
- Make each object storage solution work as efficiently as possible, for us and our customers
- Provide a simple, consistent and intuitive developer experience regardless of object storage solution being used.
The solution we arrived at works, by having the meta-data API provide custom location headers x-iflo-object-location that contain pre-authenticated links to the respective objects. This allows a developer to perform a GET on the link to download or a PUT on the link to upload without ever needing to know what object store service they are interacting with. No other headers or parameters are required when interacting with these links.
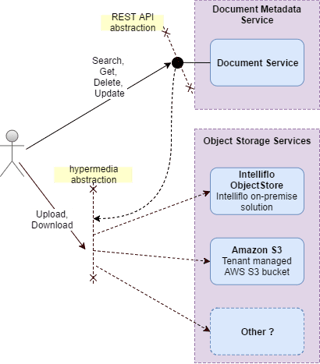
The key characteristics of this solution are as follows:
- Developers use and understand a single document metadata API
- Object-Stores are abstracted via hypermedia links and are completely transparent providing a consistent experience regardless of object storage system being used.
- Documents destined for a specific object store go directly to that object store. In the case of S3 these documents go to S3 without traversing our systems, as they previously did, making the upload/download faster, more efficient and less costly to us.
- Uploads and downloads are as simple as they can get over HTTP - no requirement for headers or authentication and no multi-part or deep understanding of HTTP protocol required.
How to use the APIs
All the APIs are documented in https://developer.intelliflo.com but the following is a more detailed overview using typical use cases.
We will look at most common use cases:
- creating a client document,
- uploading the associated physical document object,
- retrieving an existing document record
- downloading it's associated object.
I will also touch on some of the more detailed aspects of the metadata, what they are and how you can use it.
I will make some assumptions that you understand how our OAuth authentication works and that you have a valid bearer token plus Api key ready to go...
Creating a new Client Document
Assuming you know the clientId of the client that you wish to add a document to, you will need to perform a POST on the following URL /clients/clientId/documents providing the necessary path and body parameters.
Request:
POST /v2/clients/87609/documents HTTP/1.1
Host: api.intelliflo.com
x-api-key: hZiGhx...
Authorization: Bearer eyJ0eX...
Content-Type: application/json
Accept: application/json
{
"title":"A new document",
"description":"A shiny new document"
}
Response:
HTTP/1.1 201 Created
Content-Length: 436
Content-Type: application/json
Location: https://api.intelliflo.com/v2/clients/87609/documents/66401752
x-iflo-object-location: https://api.intelliflo.com/v2/objects/99/1023c7d3-bdbe-433a-b41a-ea788c4fca
b9?iflo_access_key=VfgIAASADF&expires=1495037239&signature=j3cdlDtdSt2
{
"id": 66401752,
"href": "https://api.intelliflo.com/v2/clients/87609/documents/66401752",
"title": "A new document",
"description": "A shiny new document",
"createdAt": "2017-05-17T15:52:18.9364967Z",
"properties": {},
"object": {
"key": "99/1023c7d3-bdbe-433a-b41a-ea788c4fcab9",
"href": "https://api.intelliflo.com/v2/clients/87609/documents/66401752/object",
"filename": "1023c7d3-bdbe-433a-b41a-ea788c4fcab9",
"content_length": 0,
"provider": "Default"
}
}
So as you can see we have successfully created a document resource (the metadata) and we have a Location header URI pointing to our newly created resource.
Uploading the Object
Now we need to upload the associated physical object (some sort of text, pdf, word file etc) and as you can see (highlighted above) there is an x-iflo-object-location header in the response that contains a link to the object resource. This link is pre-authenticated using a key, signature and an expiry. The link cannot be tampered with and will expire after the date specified (15 min) so you will have 15 minutes to initiate the upload. If this does expire before you get to use it, you can obtain a fresh link by doing a GET on the document resource and using the same header from that response.
To initiate the upload all we need to do is do a PUT on that link.
Request:
PUT /v2/objects/99/1023c7d3-bdbe-433a-b41a-ea788c4fcab9?iflo_access_key=VfgIAASADF&expires=14950372
39&signature=j3cdlDtdSt2 HTTP/1.1
Host: api.intelliflo.com
<object bytes>
Response:
HTTP/1.1 204 No Content
Content-Length: 0
And that is it, we have a document uploaded against a client record.
Retrieving an existing Client Document
Using the document you just created and uploaded, let's look at how we can retrieve/download it again. Using the same clientId and the new documentId from the response of your very first POST above, you can perform a GET on the following URL https://api.intelliflo.com/v2/clients/87609/documents/66401752. You can get this link from the Location header of that response.
Request:
GET /v2/clients/87609/documents/66401752 HTTP/1.1
Host: api.intelliflo.com
x-api-key: hZiGhx...
Authorization: Bearer eyJ0eX...
Accept: application/json
Response:
HTTP/1.1 200 Ok
Content-Length: 436
Content-Type: application/json
Location: https://api.intelliflo.com/v2/clients/87609/documents/66401752
x-iflo-object-location: https://api.intelliflo.com/v2/objects/99/1023c7d3-bdbe-433a-b41a-ea788ca
b9?iflo_access_key=VfgIAASADF&expires=1495037239&signature=j3jutlDtdSt2
{
"id": 66401752,
"href": "https://api.intelliflo.com/v2/clients/87609/documents/66401752",
"title": "A new document",
"description": "A shiny new document",
"createdAt": "2017-05-17T15:52:18.9364967Z",
"properties": {},
"object": {
"key": "99/1023c7d3-bdbe-433a-b41a-ea788c4fcab9",
"href": "https://api.intelliflo.com/v2/clients/87609/documents/66401752/object",
"filename": "1023c7d3-bdbe-433a-b41a-ea788c4fcab9",
"content_length": 0,
"provider": "Default"
}
}
Now that we have retrieved the document metadata we will have the x-iflo-object-location header that contains the link we can use to download the document object. Note: It is important to remember that GET and PUT links are different and are not interchangeable. So lets download the object...
Request:
GET /v2/clients/87609/documents/66401752 HTTP/1.1
Host: api.intelliflo.com
This request required no explicit headers and could be used directly in a browser window for instance. The request illustrated above shows what the request would look like on the wire.
Response:
HTTP/1.1 200 Ok
Content-Length: 876756
Content-Type: application/object-stream
<bytes>
The response is the byte stream of the document and the content type will either be application/octet-stream or a value inferred by the file extension or a parameter provided on the querystring.
And that is all there is to uploading and downloading documents (at least for the most common use cases).
Metadata property details
I used the simplest options in the use cases above to focus on the interactions however there are other properties in the metadata that are worth knowing about. Consider the following request body:
{
"title":"A new document",
"description":"A shiny new document",
"properties":{
"_fileType.name": "Bank Statement",
"_subCategory.name": "Third Party",
"_category.name": "Financials"
},
"object":{
"original_filename":"foo.txt"
} ,
"linked_entities":[
{
"id" : 123,
"type" : "Plan"
}
]
}
The properties map is used for key value style metadata. Currently though, it can only be used for internal values that are used by IntelligentOffice namely FileType, Category and SubCategory. Future plans are to allow custom user defined keys which will allow for use cases like tagging etc.
The object property is a reference to the actual physical object stored and for the most part is read only and the details of which are constructed and maintained by the system. The original_filename however can optionally be written to, if you want to store the original filename or a friendly name - this can be useful when downloading the file to disk later or in combination with content-disposition headers.
The linked_entities array is used to store links to another resource/entity in the system. The current implementation is limited to a single entry but may be extended in the future. Possible values for the type property are: Client, Plan, Fee, Retainer, Task, Adviser, Account, Lead, Complaint, AdviserQualification, QuoteItem, Quote, Opportunity, AdviceCase, QuoteResult, FinancialPlanningSession, QuoteSummary, Appointment.
Notes on Security
As mentioned above the links that are provided in headers or redirects are pre-authenticated. This is achieved using a signature which is created with a HMAC-SHA256 hash of the URL and specific headers including the verb. It also contains an expiry on the querystring which is also contained in the hash and is set at 15 minutes. These links can then be used with out any further authorisation headers or mechanisms for the duration of the expiry. It is therefore possible to share these links with others and they will be able to access the contents providing the link has not expired. For instance a download link (GET) can be downloaded directly from a browser location bar. Note: All these links are transferred between client and server over a TLS encrypted channel and are not exposed unless you explicitly share them yourself.
The hashing contents and approach between the Intelliflo on-premise storage solution and Amazon S3 use similar approaches and algorithms except Amazon S3 uses the AWS access key and AWS secret key to validate signatures whereas Intelliflo use secret we rotate frequently and the combination of a dynamically generated but deterministic iflo_access_key to do the same. The hash signatures ensure the links cannot be tampered with and this is verified by re-caluclating and comparing the hashes when requetss are made on these links.
Wrapping up...
Please give these and our other APIs a try and let us know what you think (or if you have any issues), by mailing us at developer@intelliflo.com.
We have a pretty exciting API roadmap for the next few months which I hope to share in the comming weeks. In the meantime we will notify our mailing list when we release stuff and update this blog when there is something interesting to share. Happy coding...