We've been very busy at Intelliflo over the last few years re-engineering our platform. We are now releasing our public API which is a huge and exciting milestone in our journey that has included new products, a new platform architecture and an API first strategy. The intention to release an open API has been previously anounced and if you follow fin tech news or attended our 'Change the Game' conferences you may have already heard about our API and the significance this has in our sector. What you probably aren't aware of is the back story of how our API platform came to be and the engineering led journey we've been on over the last 6 years. This post serves as an open account of that journey. Since this is our first post on this blog it is also worth mentioning that this is a technology blog and is written by members of our engineering teams so expect the content to be technical in nature.
< 2010 - The early days
With today's API economy a lot of startups begin their journeys with an 'API first' strategy which allows them to build apps that target many platforms and devices but also carry the inherent extensibility and connectivity that APIs bring. Often the API itself becomes the key product that drives revenue and we have certainly seen this happen a few times, so 'API First' can be a great strategy if you are starting out.
Like most companies more than a few years old we did not start like this, we spent most of our initial decade of existence in the trenches rapidly building the IntelligentOffice (IO) web application with a focus on delivering the features our clients were asking for and gaining market share. We have been rather successful in doing this, and have developed a market leading web application that now serves over 1,600 UK advice firms and we are growing rapidly.
2010 - Facing the challenges
IO is a large and mostly monolithic web application (~2.7 million lines of code) that has a very wide feature set, from CRM and Compliance through to Financial Planning, Trading and much more. Back in 2010 it was also our only product. Much of what the application did was integrate with other systems so we were no strangers to working with, and building APIs. In fact with over 150 separate integrations we had quite a lot of APIs but these were all very much geared towards specific and narrow use cases, weren't particularly friendly to use and were not part of any long term API strategy at the time.
Building a single monolithic application starts out being very natural and productive but as the application grows, change becomes difficult and risky and ultimately slows you down considerably. Intelliflo as a company were growing fast and the pressure to deliver features and scale to our growing customer base grew with it. We were seeing rapid change brought about by regulation changes, new customer requirements and a changing financial market that brought new and exciting opportunities.
These growth challenges started to highlight the need for a new architecture, one that would be more modular and service oriented that allowed us to readily accept change and allow us to scale our systems to match our growth. A vision we eventually started to call 'API Platform Services', slowly started to emerge where we would have a platform that would encapsulate all the capability that we built, and expose this via a set of APIs to our products internally but also extend to new devices, partners and our customers. Nothing unique or ground breaking in terms of systems design thinking, but for us, this felt a long way away at the time.
As an engineering team we have a lot of freedom and are empowered to drive change at Intelliflo but this was an enormous and daunting challenge that would not happen overnight.
We knew we would have to iterate towards this goal over many years, slowly driving changes through funded and strategic project opportunities. It would ultimately be an engineering led journey that would realise this vision.
2010 Q2 - New products and devices
Our journey towards an API architecture started in and around 2010 when we began designing our consumer facing product: Personal Finance Portal (PFP). One of the key requirements for the engineering team back then was to deliver a mobile experience that complimented the fully fledged web application. Our first mobile application was an HTML5 single page web application (SPA) written mostly in Javascript that was engineered specifically for mobile devices. In hindsight we should have built this as a native app, something we would remedy later, but I digress. At this point an API was an obvious if not essential solution and the first version of this API was released in 2011 along with PFP version 1.
The first iteration
This first incarnation of our API was 'mostly RESTful' in as much as it was resource focused, served JSON and generally adhered to RESTful practises. It was also superfast and well-designed for its use case but it did suffer from a few design flaws that would ultimately lead to a rebuild and eventually a new and bolder architecture - but more on that later.
The first flaw was that we used a custom authentication strategy, one shared with the PFP web application and hence use forms based authentication and opaque cookie tokens, not a great mechanism for a good API development experience. Given our mobile app was web based this was a quick win at the time when we were very focussed on shipping product, but would ultimately mean that we couldn't release this API for general consumption, at least until we provided a more suitable authentication story.
The second flaw was that we built the API over the top of a replicated data backend. We used replicated and transformed data via an ETL process, inspired by a CQRS style architecture, but mostly borrowed from our existing data warehouse infrastructure. There was a real concern at the time that PFP development (changes) and the eventual operational load may destabilise the IO product or impact our existing customers. IO after all is, and remains, our core product.
PFP at the time was an experimental consumer app strategy to test the market and we had very little idea what the adoption would be like, so potential impact to our core product was a concern. The first PFP app was also mostly designed to be a read only user experience so at the time this architecture felt like the best approach but we knew it would be temporary and that we would have to solve these issues if we were to continue our API journey beyond this first version.
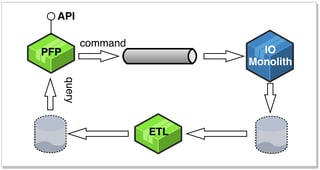
Using a replicated view store had mixed results. On the downsides it meant that because the write operations were asynchronous we had to deal with eventual consistency. A lot of the UI work that should have been quite simple, turned out to be quite challenging because of this, especially since this was something new to all involved. Working with replication transforms and dealing with asynchronous message queues became a point of friction for the team at a time when they really wanted to move quickly.
On the upsides it did mean that we could optimise read performance of the API and scale PFP and IO asymmetrically as needed. It also meant that because the API was built on a separate code base and backend we could isolate the risk of change caused by development and provide better resilience from faults caused by each system on each other. Although this architecture would prove unsuitable for where we eventually needed to be, we learnt valuable lessons from this design and these architectural qualities would remain important and influence our future system design decisions.
2014 - PFP v2 and APIs as a platform capability
After running PFP 1 in production for a few years we watched the personal finance space mature and explode with fin tech startups delivering new and innovative solutions on both web and native mobile platforms. We had big plans of our own but we would need to move fast and to do that we needed to remove architectural impediments and technical debt that stood in the way of our ambitions. Most importantly we needed to innovate quickly and support a rapid pace of development to catch the market.
The design thinking for the next major version of PFP started pretty much immediately after we released version 1. An enormous amount of effort went into this design including verifying our ideas with industry experts and clients and partners. During this period our platform engineering team used this opportunity to put in place the building blocks that would progress our API architecture and apply some of the learnings from the previous iteration.
We solved the authentication problem by introducing a set of fully OAuth2 and OpenId Connect compliant Identity and membership services. Initially this would provide authentication and authorisation for PFP and our APIs but eventually we would migrate IO over, once these systems proved stable and when an opportunity presented itself. The intention here was to centralise and consolidate our identity strategy across all our products and the platform itself. This would afford us many other benefits in the future but a subject matter for a future post perhaps.
During the design phase we also realised that a lot of proposed build was new functionality. This was significant as we knew that working on a very actively developed monolith was quite slow and had inherent risks as mentioned earlier, so we saw an opportunity to isolate this new development from the main IO app. We explored various options but it was a microservices architecture, being made popular at the time by the likes of Amazon and Netflix that ultimately seemed like a promising solution to experiment with. The idea being that; if we sufficiently decoupled our architecture we could minimise impact to other teams, avoid the risk and cost associated with change inherent in our large existing application, and hopefully move much faster. The idea seemed simple enough, the reality proved much more challenging.
2015 Q1 - Microservices
We experimented with Microservices by delivering a few key features as standalone services - Yodlee integration, branding, payments, catalog and secure messaging were the first candidates. This worked well for us, although much of the anticipated velocity gains were probably eaten up by the hard lessons associated with cutting your teeth on a distributed architecture for the first time. We learnt that building and operating a distributed architecture is complex and comes with its fair share of hard and painful lessons many of which we are still learning, but again a subject for future posts. Along side the architectural changes we were also transforming the way we delivered software. We were moving away from large quaterly releases to a continuous delivery model where we would deliver value as soon as it was 'Done'. Our journey to CD was paved with many lessons but has completely transformed how we think and approach almost everything we do now. We hope to do a series of posts to cover this in detail soon.
At this point we were tackling a complex set of challenges in architecture, product design and delivery. To give us time to focus on these challenges and shorten the time to market we outsourced the development build of the front ends - both web, Android and iOS apps (yes native this time) to 3rd parties. This meant we could parallelise our efforts at the expense of relinquishing some control of the front end engineering efforts (which we would take ownership of sometime before the release date). This came with its own challenges but one benefit this did afford us, is that it was a good exercise in understanding the needs of 3rd party developers so we were forced into thinking about things like API documentation and how our APIs would be used in the real world very early on. We built Swagger (Open API Specification) metadata directly into all our services to primarily provide documentation generation. It turns out that having APIs fully defined by meta data was a really good idea as it has afforded us so many other opportunities in areas such as automation and testing and has helped shape how we approach API development itself, via a developer workflow we now call meta driven development MDD.
Logging, Monitoring and Health
Distributed architectures bring operational complexity. Trying to rationalise about how the system is behaving is much more challenging when you add more moving parts. To help with this, we added health checks and metrics endpoints to each service which we feed into monitoring tools and load balancers to ensure that systems can react automatically to failures or notify humans when appropriate. We also massively increased our reliance on logging by fowarding and ingesting as much as we feasibly could into Splunk where we can search and analyse issues and behaviour in real time with the goal of minimising the MTTR (Mean Time To Resolution).
Requests to our APIs can result in many internal API calls, as services collaborate internally to complete the specific task. To trace these distributed call chains we inserted a correlation identifier into request headers, as they enter our data centers, and then propagated these headers through all onward requests. All log lines include this correlation_id allowing us to easily trace the request as it moves through our systems. Using Splunk, we are able to build behavioural timelines, understand latency, and track many other useful trends in real time whilst comparing this to previous or 'normal' behaviour.
The ability to make sense of what logs and machine data are telling us, in real time, soon became an operational requirement for all new build and developers produce specific operational dashboards as part of the standard workflow, defined in our 'Defintion of Done'. Our use of machine data and Splunk would soon move well beyond our initial MTTR use case and into all aspects of our business such as usage profiling, continuous delivery and customer health.
We were ready to go live...
2015 Q2 - PFP v2 goes live
PFP version 2 went live in August 2015 with an entirely new web application and native mobile apps. These apps were all built on top of REST APIs delivered on a new microservice architecture which formed the beginning of an API platform that would soon become the foundation underpinning all future product build at Intelliflo. At this point our confidence in our design decisions was growing but we still didn't have all the pieces to truly take an API, as a product, to market.
2016 Q1 - A Unified API
With PFP v2 released we started to think about the commercial and operational aspects of taking our API to market. Things like traffic management, credential management, rate limiting, and the overall developer experience began to get focus.
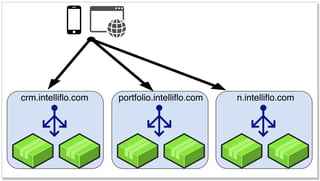
We started out routing traffic via different domain names attributed to every service behind load balancers. This was fine to start with but the initial 5 or 6 microservices quickly turned into 50+ and this strategy became cumbersome to configure and manage. More importantly it forced 3rd party developers that worked against our APIs to understand what service they needed to talk to and quite often these boundaries, which made sense to us, were very unintuitive to them. We felt we had a well thought out global Uri namespace however these Uri's were spread across services even though they seemed very closely related.
As a quick example, a client record could be retrieved from the CRM service, however a client's plans needed to be retrieved from the Portfolio service eg:
https://crm.intelliflo.com/clients/123
https://portfolio.intelliflo.com/clients/123/plans.
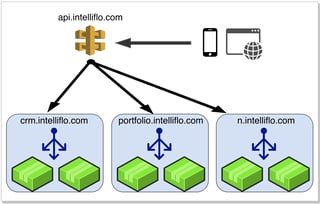
We felt that in order to provide a better and more intuitive developer experience we needed to unify our APIs into a single Uri namespace and abstract the concept of services away as much as possible.
We used an API gateway (AWS API Gateway) to map our Uri's to our backend services and unify our API over a single domain. Uri's were now decoupled from service domains so the examples above now became:
https://api.intelliflo.com/clients/123
https://api.intelliflo.com/clients/123/plans
Considering we currently have 50 odd microservices and over 400 endpoints we felt this would really make a huge difference to what a developer, consuming our APIs, would need to understand. Rate limiting, API tokens and broader traffic management were also now possible via the gateway too, with minimal effort.
2016 - Q2 - Scopes and Reach
Another problem we faced was that each service had an OAuth scope that needed to be requested as part of the OAuth authorisation flow in order to use the service. This seemed like a reasonable approach early on but the problems became evident quite quickly - way too many scopes that were based on service boundaries. This felt like a leaky abstraction and a concept developers really didn’t need to know about and would mean changes in this area could break API consumers.
To remedy this we reorganised our authorisation Scopes to map to real world and business contexts instead, which made them broader, decoupled and meant we had better control of which scopes we wanted to introduce .
So instead of "crm" and "portfolio" scopes we would have "client_data" and "client_financial_data" respectively. These scopes would then easily transcend service boundaries and felt much more intuitive.
OAuth scopes were great for controlling access to the surface area of your APIs or 'breadth', however we needed a way to ensure we could also control access to the 'depth' of data exposed via APIs. For internal use our API clients could access all data if needed, even across tenants, but we needed to ensure that client credentials we gave to 3rd parties provided access to only the data that they were allowed to see. We introduced a concept we called "reach" which allowed us to talk about this as another dimension to scopes that would be baked into API authorisation flows. The details of how this works is best discussed in depth in another blog post but an illustration of how this mapped across some of the scopes and OAuth authorisation flows can be seen below.
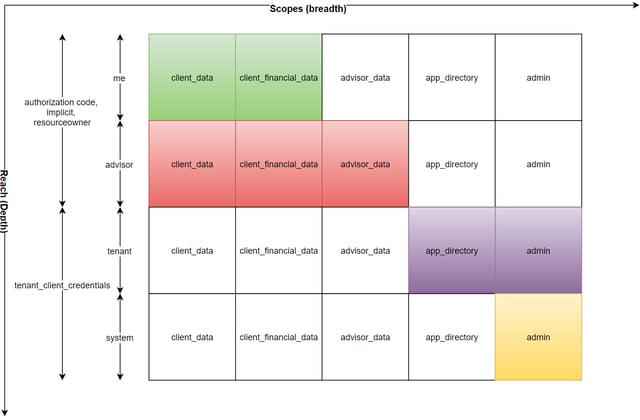
Reach descriptions:
- "me" is for data associated with the person calling the API i.e. "my data". Great for personal, consumer facing applications.
- "adviser" extends "me" by providing access to data associated with persons related to the adviser in a professional sense i.e. his/her clients etc.
- "tenant" provides access to all data belonging to a single tenant in our system which is typically an organisation.
- "system" is unrestricted access to all data within the system. This reach is for specific internal applications only and not available to 3rd parties.
2016 Q3 - Developer Experience
Currently we are heavily focussed on making our API's as accessible as possible and providing the best developer experience possible. Our go live MVP was to deliver a developer hub that contained API documentation and searchable API references.
This is something we are now actively developing but we are happy to announce that the first version of the Intelliflo developer hub is now live in beta at https://developer.intelliflo.com. Please take a look and let us know what you think.
Future plans are to improve the documentation based on customer feedback, include example code, credential and token management workflows as well as an application market place where developers can submit applications that integrate into our core products or target our users.
Whats next…?
After such a long journey and so much learnt and achieved we are of course never done, in fact our ambitions and plans for the future are bigger than ever. We have a rich and exciting backlog of features and improvements in all areas of our APIs that we hope to bring to market as soon as possible.
Our first public API release exposes 143 resources with 259 operations across only 10 individual services. We have another ~40 services with hundreds more resources that we currently use internally and we plan to release most of these publicly over time. Of course we are continuing to build new services and functionality so this API surface area will continue to grow.
Other noteworthy future releases will include WebHooks and an application market place for all the cool stuff we hope people build with our APIs.
The momentum and excitement that we have built internally around our new platform has meant that we think and build with an 'API first' strategy in almost everything that we do now. This means that the huge amount of investment we put into our core products like PFP and IO naturally produce APIs that we make available to customers, partners and developers to use themselves.
This is the first post to our Intelliflo tech blog and we plan to publish much more about our progress, future challenges and any cool stuff we release, so stay tuned. Finally if you are interested in what we do and think you can help us, we are hiring.